The complete step-by-step guide to create and deploy your multi-language website - Part 4

This is the forth post on how to create your website step by step!
This is the forth post on how to create your website step by step!
This is the second post on how to create your website step by step!

Julia is a programming language that I heard a lot for some time now and I knew it deserved my attention. However, a number of libraries and frameworks for machine learning and deep learning keep emerging and I ended up prioritizing them first.

This is the forth post on my internship on the Outreachy Program with Project Jupyter. The first, the second and third post are already available, if you want to understand the big picture.
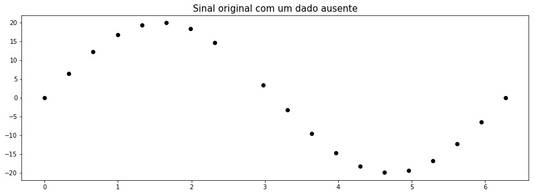
AKA magics to plug holes in your dataset

In today’s development, tests are a fundamental tool for keeping things nice and easy and to keep programmer’s sanity. I’ve been using a set of tools for developing my web applications with Django and it is time for me to share a little bit about them.

One year ago I started my new job as a Backend Python Developer. I have dropped a career, a profession and I almost drop my master degree. When everything happened, I think I didn’t understand the proportions that decision would have in my life. Now, one year later, I want to tell you a little bit about what happened this year.
This is the third post on how to create your website step by step! In this post, we will allow that people can comment on your awesome posts!
I’ve written over and over about why you should have a blog and write on it. I made this website using nothing but free tools. The only thing I paid was my domain (leportella.com) and I find this super cool! 🤩
When I created my website I realied on a lot of different tutorials, one for each part of it. Because the process of creating it can be quite tricky, I decided to create a full, step-by-step tutorial.

My participation in technology communities over the last 3 years, lead me to notice that it’s always tricky to show to companies which don’t interact with this technology ecosystem, how beneficial it is for them to get involved. Many people (developers or not) struggle within their companies, trying to show how much they could benefit from this.

When you start entering the data science world, things can become really messy. There are thousands of concepts and meanings, most of them thrown at you at the same time.
Hello there! This is the second report on my work on Outreachy internship program. On the first report I told a little bit on how I got into the program, which problem I am focusing and my first tasks :).

I started working with MongoDB for fun and for some side projects in the last year. The main idea of using MongoDB is its flexibility. The pymongo library is really nice for getting some information, but on a project more complex, we may need something a little more intense. A nice alternative is the MongoEngine library, which is an Object-Document Mapper (ODM), which treats MongoDB documents as a kind of ORM.

Last year (2021) I decided to add GoatCounter as the analytics tool for my blog. There were a couple of reasons why I did it, but the main one is privacy. I am trying to move a bit away from Google, and I wanted something different.

I was recently helping a friend who was transitioning from Matlab to Python. Giving him some tips, I realized that many of the cool nuances I learned in Python were taught me by someone in a “do you know that?” style or to solve a very specific problem that could be solved more simply.
When helping this friend who is there on the other side of the world, I remembered the time when there was no one to teach me a cool trick and, in fact, I didn’t even know it could exist.
This is the fifth post on my internship on the Outreachy Program with Project Jupyter. The previous posts are available and should be read in order if you want to understand the big picture:


Native Authenticator was pretty advanced, but we still needed more information available on the documentation. And this got me thinking: what is relevant to make a good documentation? I know some good examples of a good documentation and an big amount of awful ones. I read an article in portuguese on how to do a good documentation but it still didn’t click to me.
Hi :)
On November I discovered that I was selected for the Outreachy internship program for the batch of December 2018 to March 2019.

Most of all Django tutorials teach us how to return HTML as response to a request. Sometimes, it is useful to make it a little more RESTful. One option is to use Django REST Framework but sometimes you need something a little bit simpler. Then you have Restless. Restless is a miniframework made by Daniel Lindsley based on what he learned by making Tastypie and some other REST libraries.