The most common data science tools

When you start entering the data science world, things can become really messy. There are thousands of concepts and meanings, most of them thrown at you at the same time.
Usually, most tutorials and texts focus on languages to be studied but this time I decided to bring something different. In this text, I brought some “simple” explanation for some of the most common tools used on data science development. Although sometimes the tools is attached necessarily, the idea is to explain more about the tools then what each language can do. This is not a text about how to open a spreadsheet and process data, but where data science tools live and which has the right things for you.
Everybody ready?

Virtualenv
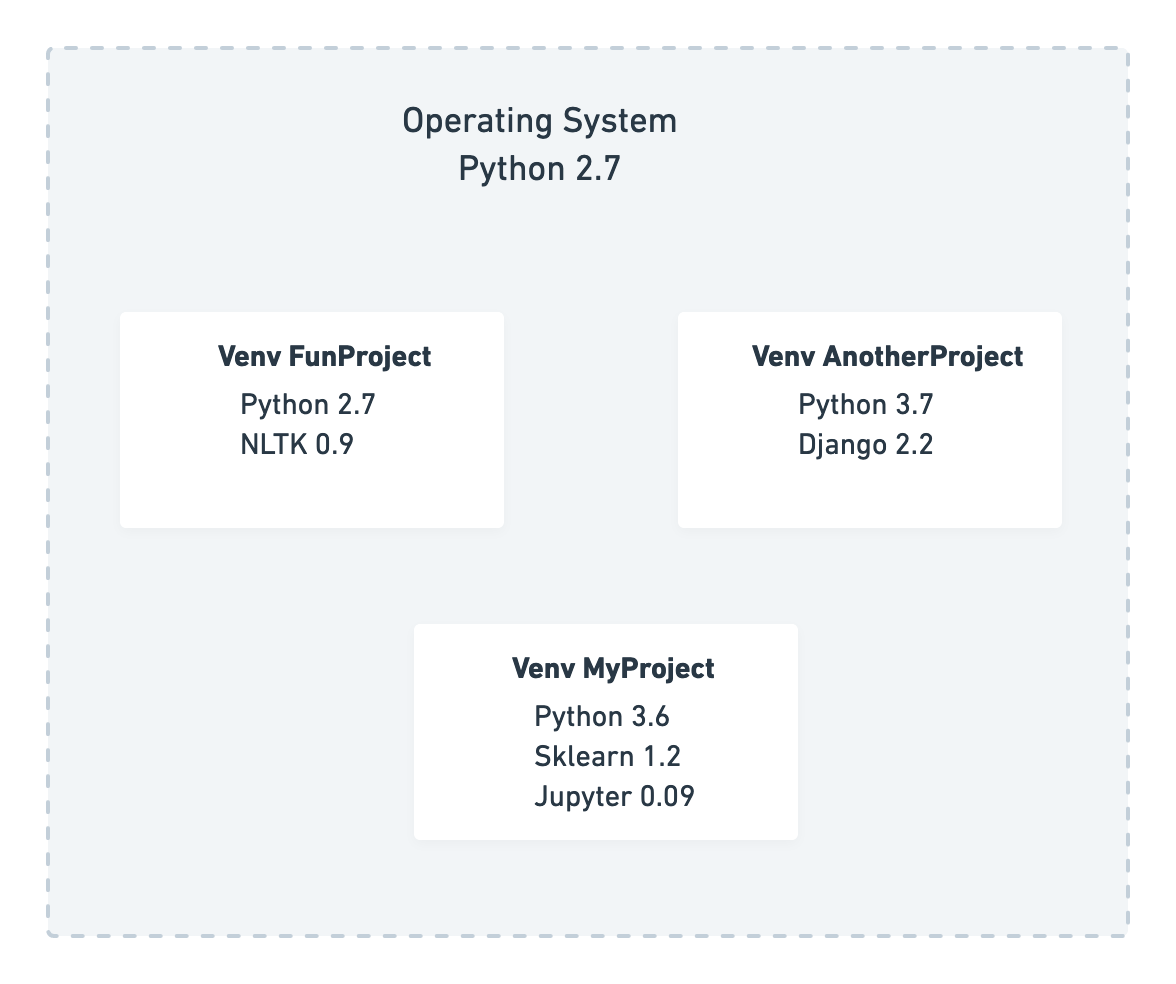
Virtualenv is a Python tool developed to isolate development environments. It is really handy when you need to isolate projects that use different versions of Python and packages. It is specially good if you consider that some operational systems use Python as a default tool. Imagine that your system uses a specific library with a specific version. Change it can cause severe complications on your whole system. So, you definetely should be careful.
Imagine that your computer (and operational system) is a huge box that has a lot of packages:

Your operational system is like a box, with a specific version of Python and the Python libraries it needs, which specific versions it needs.
Creating a virtualenv is like you created a “little box”, and inside it you can install whatever you eant: any version of Python and any version of the libraries you need. Since you created a “little box”, what’s in it is completely isolated from your general environment, and it can be easily deleted if you stop working on that project.

Since you can create multiple virtualenvs, each project can (and normally should) have its own “box”, making easier to manage packages and libraries for each project, always keeping your operational system intact.
Jupyter
Project Jupyter is an open-source project that creates tools to help people develop scientific computation and data science in an iterative way and multiple languages. Usually when people talk about Jupyter they probably are talking about Jupyter most famous tool: Jupyter Notebook.
Notebooks were created in 2014 and quickly became famous on both academic and business world. It is an development environment that allows you to write code, text, create graphics, add formulas, videos and much more in a single place. It is extremely powerful, for instance, to give lectures. All theoretical concepts and the code that show how to apply it can be in the same document. A cool example is a series of 12 notebooks made by Professor Lorena Barba that shows how to implement in Python the complex formulas of fluid dynamics. Since this is not an easy task, each notebook gets more and more complicated.

Notebook example. Each cell is independent from the other an can either contain text or code.
When you run a Jupyter server on your computer, the system will open in a browser. This makes easy for users that are not very technical or have trouble with command lines. All files are saved with the extension .ipynb and can be exported to HTML (to open in any browser) as well as to PDF.
Spyder
Spyder is an environment focused on scientific computing and data science with Python. Unlike Jupyter Notebook, Spyder is a Desktop application. The program has an area for developing your code, a terminal to run code and the script and and an area to visualize the variables that are loaded in memory.
It also has tools for checking code quality and quick shortcuts for accessing documentation, which makes life pretty easy for beginners.
A cool thing about Spyder is that it also have a plugin to use and create Jupyter Notebooks inside the Spyder platform.

Spyder interface. On the right there is the available files on the directory, next to it the script that is being developed, then error verification. On the upper right you can see variables loaded and on the lower right the terminal with the figures plotted by the script.
R-Studio
Similar what Spyder is to Python, we have R-Studio for the R language. R-Studio contains an area for script development, terminal and variables available. It is also an open-source tool and has versions for both Desktop and browser.
A cool thing of R-Studio is that it allows you to run both R and Python code at the same time :)
It also has a kind of “notebook” available, called RMarkdown (extension .rmd). This file is similar to a Markdown file, but with more options. Like Jupyter, it allows code and text to exist in the same document in an organized way. It can also be exported by HTML and PDF.

R-Studio interface. On the lower right a documentation area and access to the documents available on the directory. On the upper right you can see available variables. On the upper left the script that is being developed and on the lower left the terminal to execute commands.
MATLAB
MATLAB is a software focused on numerical calculus, based on matrixes (MATrix LABoratory). It is a proprietary software (and not a cheap one), available for Desktop and with its own language. Since the language only exists inside the software, we usually say MATLAB as a development environment and programming language. It is widely using for research by the schools, but its high costs makes it not a good tool for wide use.
It generates files with extension .m.

MATLAB interface. At left the script that is being developed, on upper center a space for plotting images, on lower center the terminal, on upper right the available variables and on lower right the history of commands typed on the terminal (command line).
Octave
GNU Octave is a computer language, developed for mathematical computing. Like MATLAB, Octave is both a development environment and a programming language. It is considered an open and very good alternative to MATLAB, since it reads the .m extension files. Among the compatibilities between Octave and MATLAB we have:
- Basic type matrices
- Support for embedded complex numbers
- Powerful mathematical functions
Differences exist, but can be worked on the software preferences.

Octave interface. On upper left the files available on current directory, on lower left the available variables and the terminal (command line) is on the right, with an image over it.
Pip
When you actually go to work with data science, you often need to use packages (also called modules or libraries) that others have created to make your life easier. Spyder and Jupyter are examples of this kind of packages.
Pip is a tool that manages the installation of Python packages. It contains over 600,000 projects, which makes it ideal to install any Python package you want.
Important: R, MATLAB, and Octave do not have specific dependency managers.
Anaconda
Anaconda is a free and open source distribution that aims to facilitate the installation, use and deploy of both R and Python data science tools in any operating environment (Windows, Linux and MacOS). Basically it is an installer that already have everything ready for you to start using and working in the area. When you install it, it usually install all main libraries and tools that you’ll probably use, like Pandas, Jupyter and Numpy. Because it handles with of a lot of things, the installation is a bit more robust and requires more space on your computer.
The Anaconda distribution is then composed of some parts, as shown in the figure below taken from the project site.

Conda
Conda is an open-source project to handle the installation of packages and any of its dependencies. It is the main basis of Anaconda as you can see on the figure above. It is, let’s say, a Pip with steroids. This is because it works for all major languages in the data analysis area: Python, R, Ruby, Lua, Scala, Java, JavaScript, C / C ++, FORTRAN.
Although it has been built as the basis of the Anaconda, it can be installed totally independent to Anaconda. It occupies far less space than the great infrastructure of Anaconda, with a very large power. Conda is especially good for managing packages that need dependency from other languages or programs. Imagine that you need to install a package that depends on a tool in Java … Installing each part can give a lot of headache, especially if we talk about Windows environment. Conda abstracts this difficulty for you.
Ah! And the conda also creates virtualenvs :)
Git and Github
Imagine that you made a beautiful and wonderful code, but your colleague had a brilliant idea and wants to test and improve your code. He/she does not need to go to your computer! It changes a file and sends the fixes to you. But how to know what he/she has done? What was changed, when and by whom exactly? That’s exactly what Git does. Git is a system that controls versions. With it it’s possible to know who changed what, when, where and all the comments that the person made while making the changes. It is one of the foundations of software development these days and data scientists should know how to work with it.
Now imagine that you made your code with a super complex analysis of a huge dataset and the analysis took forever. And then your computer died. What to do now? Sit down and cry? Not if you use an online platform to put your code! Github, like other similar platforms like Bitbucket and Gitlab, is a system that allows you to store your code online. What sets it apart from a Dropbox or Google Drive is that it implements the Git system for you. This allows all code changes and the people who made them to be stored in the cloud and not lost if someone’s computer dies. This way, you can also go back to “past versions” of your code (in case something went wrong) or find the moment when errors were introduced. It is a fundamental tool for those who want to build a portfolio :)
